
Data Drift
Practitioners of Machine Learning Engineering or Machine Learning Operations (MLOps) know the term Drift. Drift in machine learning is the change in model performance over time, due to changing realities of the world, be it concept drift or data drift. We handle drift in ML by retraining the models on newer data. Thus, over time, ML models get better. This makes ML/AI antifragile. As Nicolas Nassim Taleb says, in his book by the same name, the antifragile gains from prediction errors and randomness, in the long run. Conversely, the models that get hurt by them perish.
The Large Language Models use the entire internet data for its training. Internet has been the storehouse for all the randomness with a variety and high velocity of data. Doesn’t it imply that LLMs are the most antifragile entities? Turns out it could be the other way around. A quick eye on the recent textual content on the web can tell you that a lot of it is AI generated. With wannabe influencers out to impress, AI generated content is growing fast. The day is not far when most of the content on the web would be AI generated. What would then happen to the antifragility of LLMs? Would they keep regurgitating the same stuff over and over with no enhancement in creativity? Will this make them prone to biases?
Is your AI perplexed enough?
Nature’s recent paper on the possible AI model collapse formalizes this fear. Accordingly, AI produces gibberish when trained on too much of AI generated data. AI models learn the best from diversity. With much content generated by AI, model collapse is a possibility. The aforementioned paper shows how perplexity decreases with new generation of AI generated data.
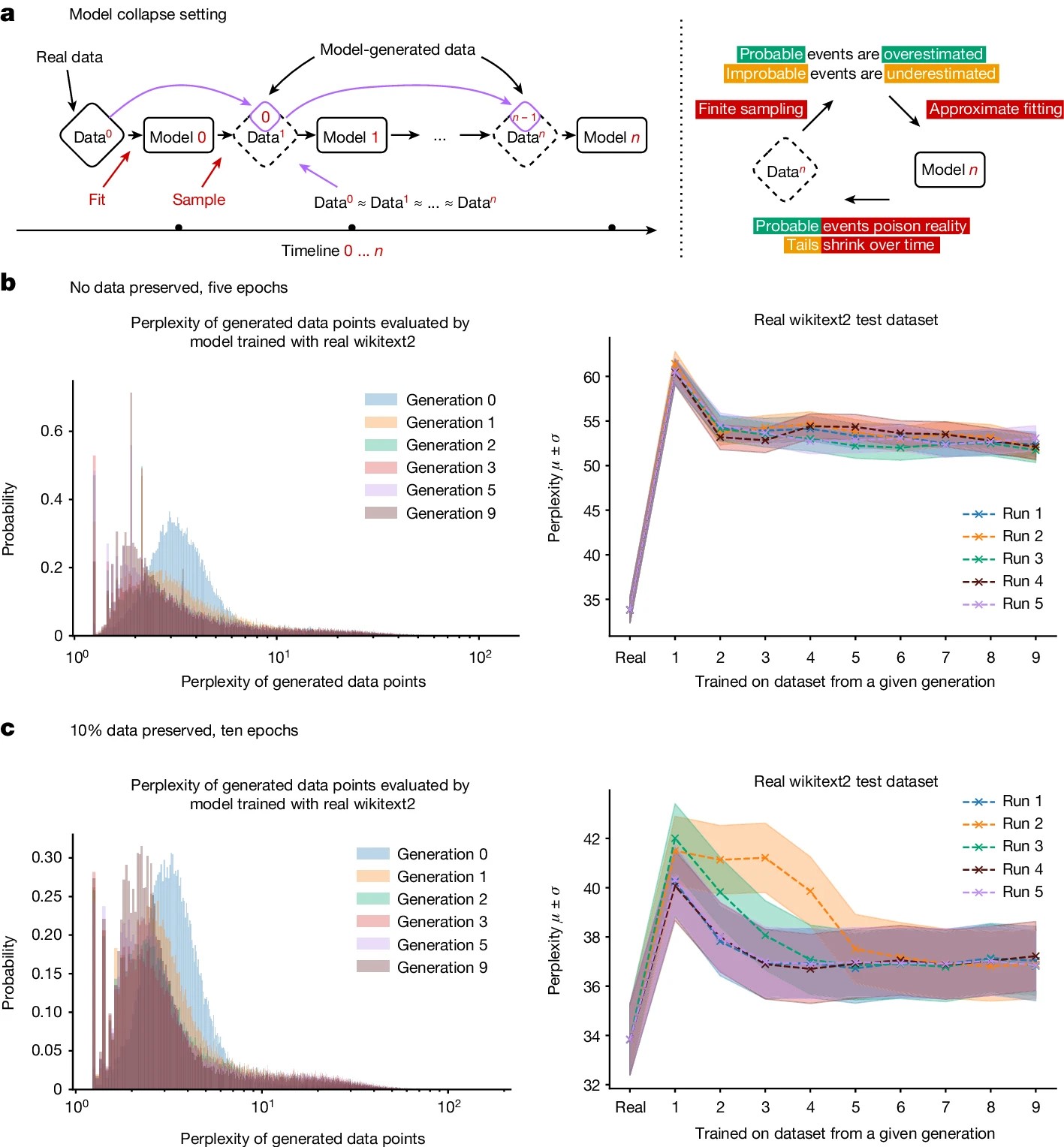
A key observation here is the Perplexity going down with successive generations of data generated by the models. Here is the mathematical representation of perplexity:

We can infer from this expression that lower the probability of the next word given the sequence, higher the perplexity. Hence, if the model gets trained on similar words over and over, the perplexity will lower and less new knowledge will be added, making it fragile.
This also conforms to Shannon’s information theory which states that information is inversely proportional to the probability of an event. Lower the probability of the word or token, higher the information it conveys. More knowledgeable the person, lesser he/she talks. Black swans convey more about the world as compared to day-to-day happenings. LLMs need newer information to stay relevant and useful.
Parallels to Human learning
Concepts in AI/ML have equivalences in human brain. I explored a few of them in this article of mine years ago: Machine Learning and Human Learning. Accordingly, concepts like bias-variance dichotomy and learning rate resonate with human learning.
Humans are antifragile. They need challenges to grow and thrive instead of comfort zones. Just like your muscle gets built by straining them. As Dr Carol Dweck says in her classic Mindset, embracing challenges and confusions (read perplexity) indicates growth mindset.
Will AI (models) collapse?
Now, let’s come to the key question. Will AI models collapse? We don’t know. Maybe not since, companies like OpenAI and Anthropic will figure out ways to avoid retraining on AI generated data. But if they don’t, will this lead to the collapse of AI, like the AI bashers would like to say? Is internet the only source of data that can be used by these models? What about proprietary data?
Ever since LLMs have turned mainstream, their usage is evolving. In 2023, they were prompted directly with all the context required. 2024 brought RAG into the picture big time, enabling them to use more reliable, propriety data. And as they say, 2025 will be the year of AI agents talking to each other to achieve an objective. LLM use has evolved from a massive model spouting next word to using external memory to tool usage to agents.
This is very similar to evolution of human thinking. Earlier, they did everything themselves. Then they evolved to use tools and storage devices and now they work in large teams to achieve their objectives.
Let’s say this loud and clear; AI is not going anywhere. However, the character will keep evolving. This will take hard engineering and creativity to make them a learn it all system instead of a know it all.
Featured Image Credit: Medium.


