Machine Learning is not only about building models but consuming them. ML Models are consumed in two ways: Batch Inferencing and Real-Time Inferencing.
In Real-Time Inferencing, results are expected in real-time. Typically, a user submits a query, and the model responds. On the other hand, in Batch Inferencing, the model does not respond in real-time. Instead, a batch or batches of data is passed to the model for scoring.
In enterprises, batches of tabular data are stored in Data warehouses, suffice traditional, descriptive analytics. However, advanced forms of analytics like Predictive Modeling need tighter integration with Machine Learning platforms. Fortunately, platforms like Azure Synapse Analytics provide a unified analytics platform. To know more about the philosophy behind Azure Synapse, here is an article.
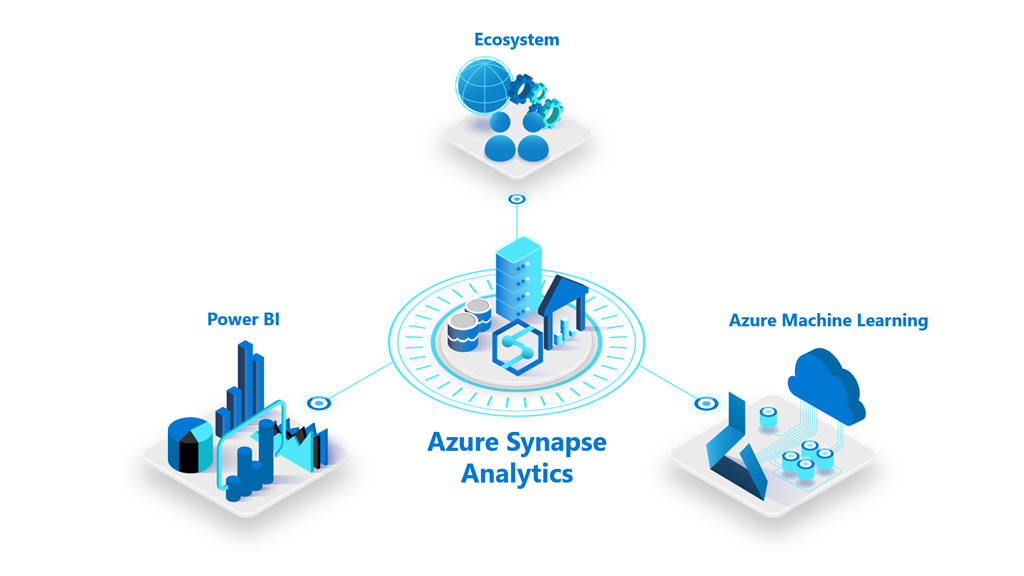
So what’s the scenario here? We will demonstrate a batch prediction scenario. A model will be trained on the California Housing Dataset, stored in Azure Synapse Data Lake, using Azure Machine Learning. This model will be scored on a batch of data from another table of the dedicated Azure Synapse SQL Pool (formerly Azure SQL DW).
For an introduction to SQL pool, read this article of ours. We assume that you have Azure Synapse Analytics workspace, a Dedicated SQL Pool and an Azure Machine Learning workspace set for this lab. Let’s layout the high-level steps:
- Load California Housing Dataset.
- Grant access to Azure Machine Learning to Azure Synapse Analytics.
- Create a Linked Service to AML workspace in Azure Synapse.
- Build the Model.
- Score the Model.
1. Load California Housing Dataset
Data forms the bedrock of Machine Learning. Hence, we will create our datasets in this first step, using Azure Synapse databases.
Azure Synapse Analytics comprises two types of Databases viz. Lake Database and SQL Database. By design, model training happens on lake database tables. On the other hand, batch inferencing happens on SQL Pool tables. For demonstration, let’s load the training data into the default lake database while the inferencing data will be loaded into the SQL pool. Let’s get started:
First, open a new notebook in the Azure Synapse studio and import all the required libraries.
import pandas as pd from sklearn.datasets import fetch_california_housing
Next, we will load the built-in scikit learn dataset, California Housing, in a Pandas Dataframe. To know more about the California dataset, read this article of ours.
# load the dataset california_housing = fetch_california_housing() pd_df_california_housing = pd.DataFrame(california_housing.data, columns = california_housing.feature_names) pd_df_california_housing['target'] = pd.Series(california_housing.target)
Now, let’s sample and split the dataset into two. 99 per cent of the data will be used for the Model Training process, while 1 per cent will be used for inference. Hence, we will use the pandas split function to do so.
pd_df_california_housing_inferencing = pd_df_california_housing.sample(frac=0.01) pd_df_california_housing_training = pd_df_california_housing.drop(pd_df_california_housing_inferencing.index)
Furthermore, we set the target column or the label column of the inferencing dataset to the default value of 0.0.
pd_df_california_housing_inferencing['target'] = 0.0
Further, we convert the pandas dataframes to spark dataframes and create a view on top of the inferencing table.
spark_df_california_housing_inferencing = spark.createDataFrame(pd_df_california_housing_inferencing)
spark_df_california_housing_training = spark.createDataFrame(pd_df_california_housing_training)
spark_df_california_housing_inferencing.createOrReplaceTempView("CaliforniaInference")
Next, we load the training table into the default lake database.
spark_df_california_housing_training.write.mode("overwrite").saveAsTable("default.CaliforniaTrain")
Lastly, we use scala context to load those dataframes directly into our Synapse SQL Pool.
%%spark
val scala_df_train = spark.sqlContext.sql ("select * from CaliforniaTrain")
scala_df_train.write.synapsesql("<your-database-name>.dbo.CaliforniaTrain", Constants.INTERNAL)
val scala_df_inference = spark.sqlContext.sql ("select * from CaliforniaInference")
scala_df_inference.write.synapsesql("SQLPool01.dbo.CaliforniaInference", Constants.INTERNAL)
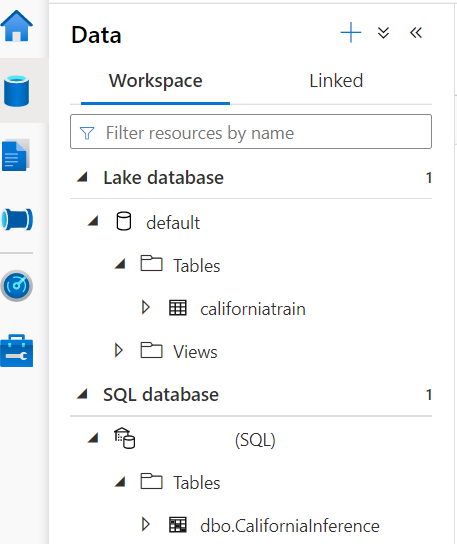
To cross-check, go to the Data section of the Azure Synapse studio.
2. Grant access to Azure Machine Learning to Azure Synapse Analytics
With the dataset in place, let’s get to the heart of the subject i.e. Azure Machine Learning integration with Azure Synapse Analytics. Although Azure Synapse Analytics uses Spark, which can be used for building ML models, it cannot be a replacement to a specialized ML platform like Azure Machine Learning. Moreover, the latter offers tools for citizen data scientists like Auto ML and Azure Machine Learning Designer. Hence, it is good to have the combined power of Azure Machine Learning and Azure Synapse Analytics at your disposal. However, before that, you need to do some preparatory work.
Go to Azure Machine Learning workspace’s access control and click on Add Role Assignment and assign the Contributor role to the synapse workspace:
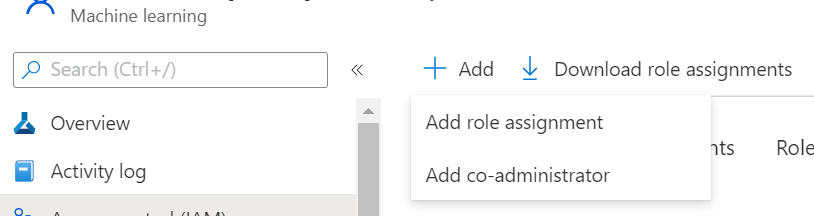
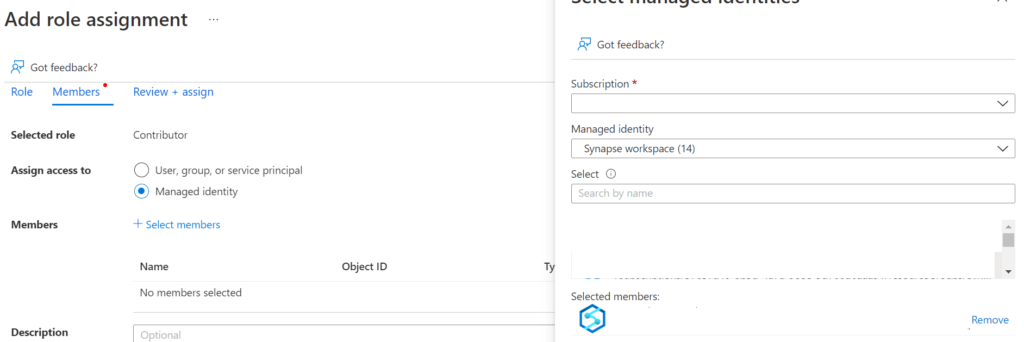
3. Create a Linked Service to AML workspace in Azure Synapse.
Next, create a linked service to AML in Azure Synapse:

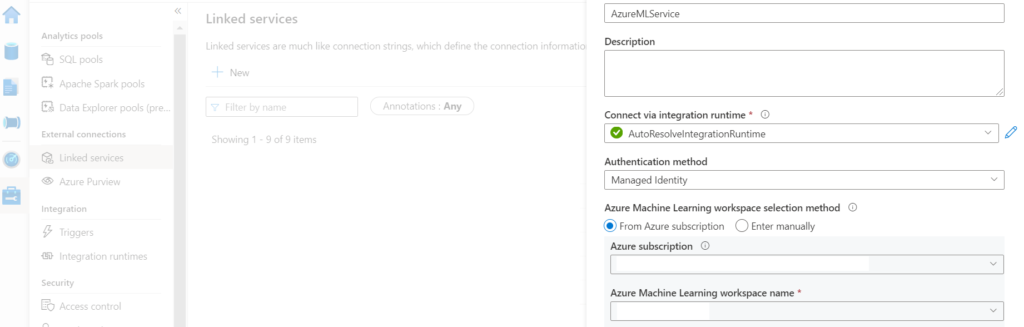
4. Build the Model.
Now, we come to the ML model training part. In this section, we will train a model using Auto ML to build an ML model. Please note that you can build a custom model in Azure Machine Learning. However, to simplify model building and to introduce the readers to AutoML, we are taking a shortcut. Here are the steps.
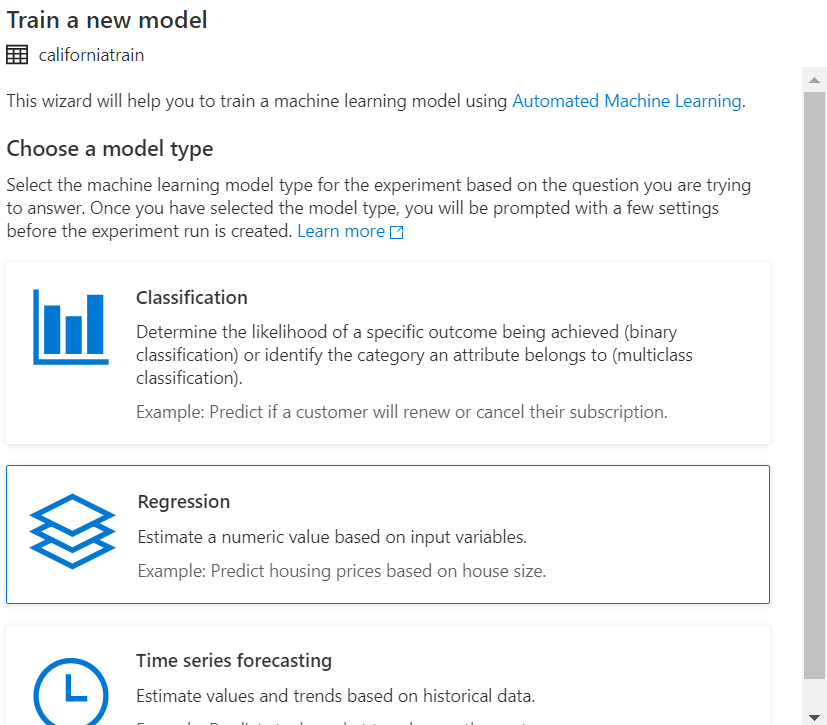
Firstly, click on the training dataset californiatrain and choose train a new model:
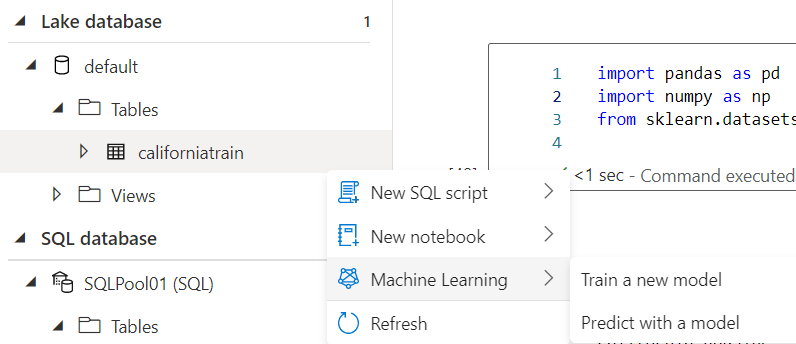
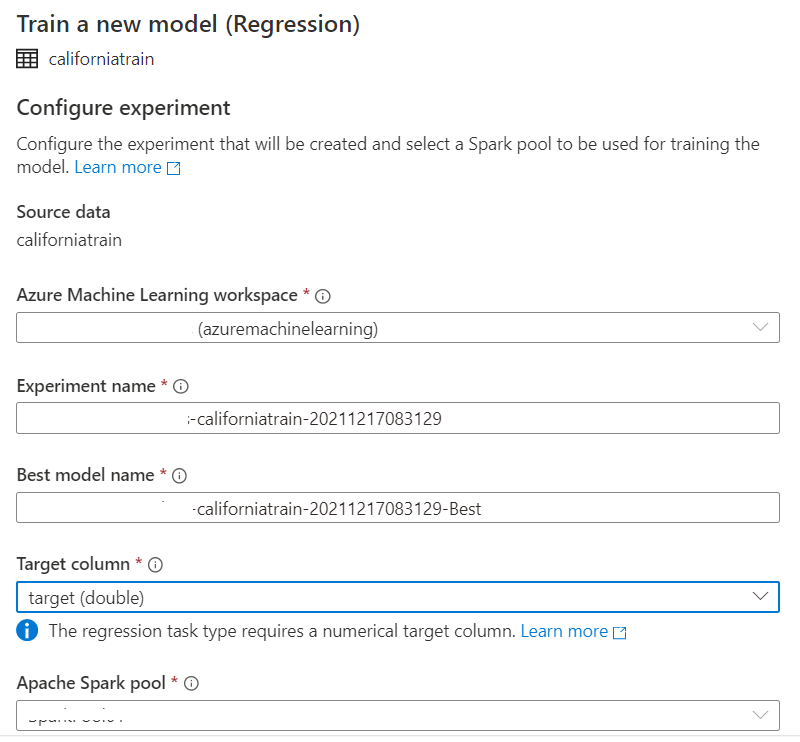
Further, choose Regression and select the below configurations before running the Auto ML:
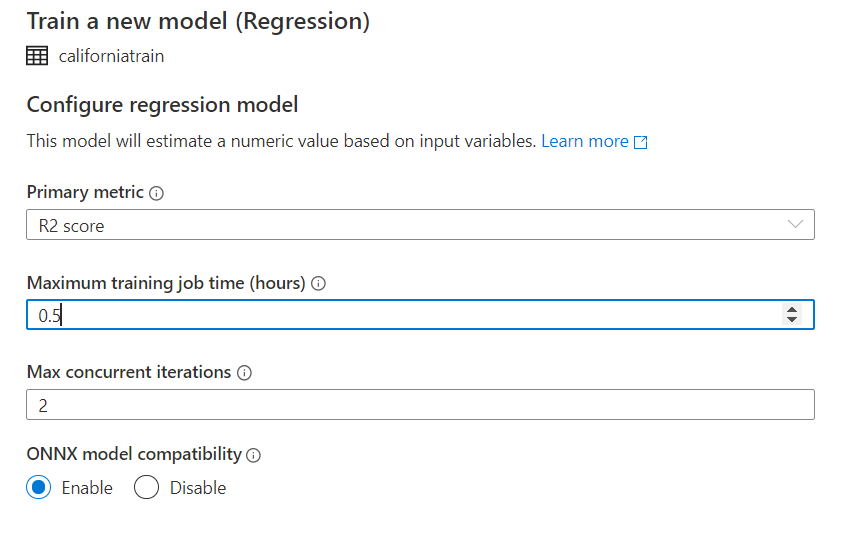
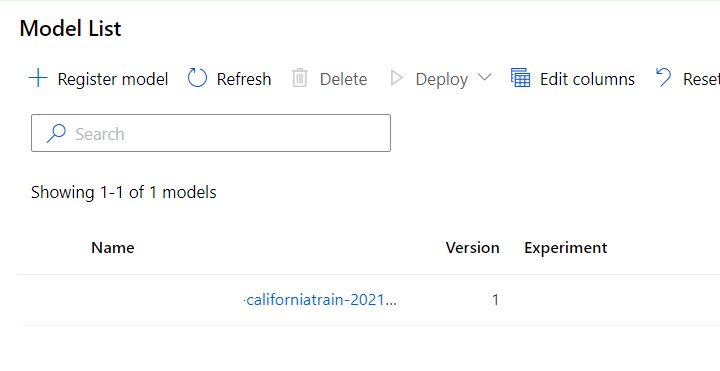
After running the AutoML job, wait for around 30 minutes to have the best model. You can view your best model registered under the Models section of Azure Machine Learning.
4. Score the Model.
Once the model is ready, click on the CaliforniaInference table. Select the Machine Learning>Predict with a model.
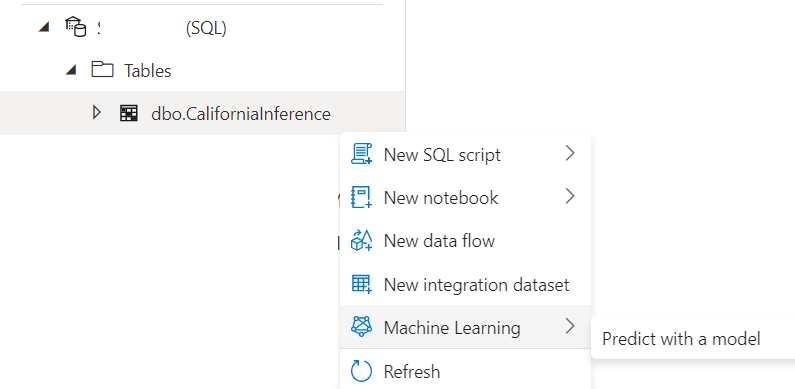
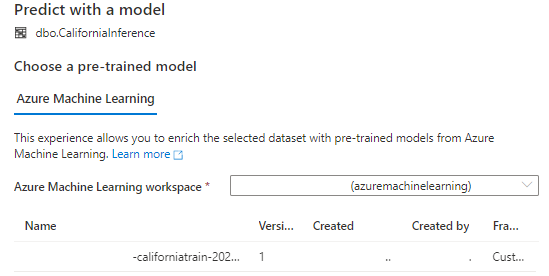
Next, select your registered model. This will open up an input/output mapping window.
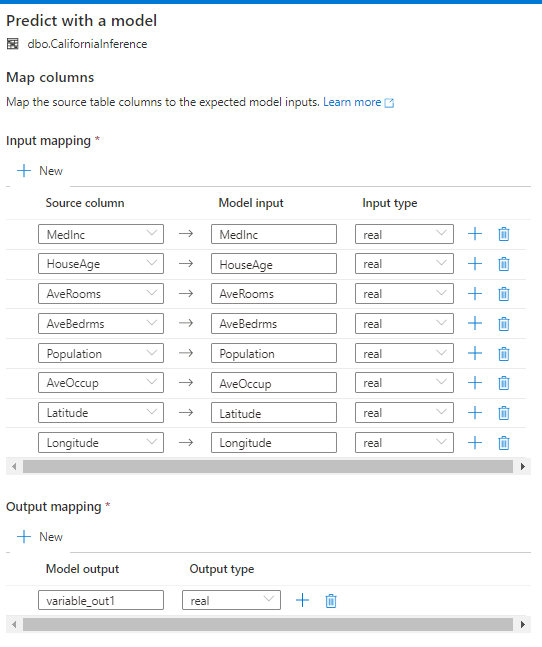
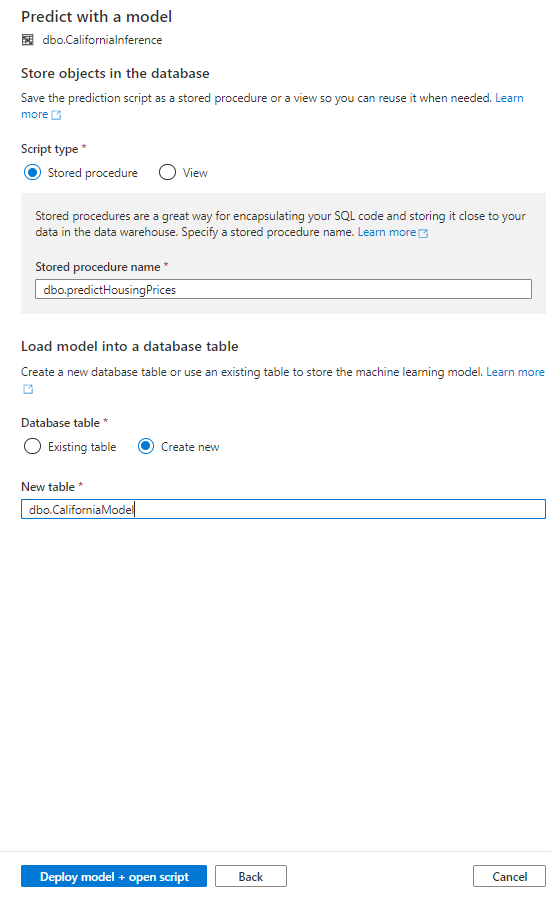

-- Create a stored procedure for storing the scoring script. CREATE PROCEDURE dbo.predictHousingPrices AS BEGIN -- Select input scoring data and assign aliases. WITH InputData AS ( SELECT CAST([MedInc] AS [real]) AS [MedInc], CAST([HouseAge] AS [real]) AS [HouseAge], CAST([AveRooms] AS [real]) AS [AveRooms], CAST([AveBedrms] AS [real]) AS [AveBedrms], CAST([Population] AS [real]) AS [Population], CAST([AveOccup] AS [real]) AS [AveOccup], CAST([Latitude] AS [real]) AS [Latitude], CAST([Longitude] AS [real]) AS [Longitude] FROM [dbo].[CaliforniaInference] ) -- Using T-SQL Predict command to score machine learning models. SELECT * FROM PREDICT (MODEL = (SELECT [model] FROM dbo.CaliforniaModel WHERE [ID] = '<YOUR-MODEL-NAME>'), DATA = InputData, RUNTIME = ONNX) WITH ([variable_out1] [real]) END GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE PROC [dbo].[predictHousingPrices] AS
BEGIN
-- Select input scoring data and assign aliases.
IF OBJECT_ID(N'tempdb..#CaliforniaInference') IS NOT NULL
DROP TABLE [dbo].[#CaliforniaInference]
SELECT
CAST([MedInc] AS [real]) AS [MedInc],
CAST([HouseAge] AS [real]) AS [HouseAge],
CAST([AveRooms] AS [real]) AS [AveRooms],
CAST([AveBedrms] AS [real]) AS [AveBedrms],
CAST([Population] AS [real]) AS [Population],
CAST([AveOccup] AS [real]) AS [AveOccup],
CAST([Latitude] AS [real]) AS [Latitude],
CAST([Longitude] AS [real]) AS [Longitude]
INTO [dbo].[#CaliforniaInference]
FROM [dbo].[CaliforniaInference]
-- Using T-SQL Predict command to score machine learning models.
IF OBJECT_ID(N'tempdb..#CaliforniaPred') IS NOT NULL
DROP TABLE [dbo].[#CaliforniaPred]
SELECT *
INTO [dbo].[#CaliforniaPred]
FROM PREDICT (MODEL = (SELECT [model] FROM dbo.CaliforniaModel WHERE [ID] = '<YOUR-MODEL-ID>'),
DATA = [dbo].[#CaliforniaInference],
RUNTIME = ONNX) WITH ([variable_out1] [real])
-- UPDATE/MERGE the Inference table.
MERGE [dbo].[CaliforniaInference] AS tgt
USING (select * from [dbo].[#CaliforniaPred]) AS source
ON
(CAST(tgt.MedInc AS [real]) = source.MedInc
and CAST(tgt.HouseAge AS [real]) = source.HouseAge
and CAST(tgt.AveRooms AS [real])= source.AveRooms
and CAST(tgt.AveBedrms AS [real])= source.AveBedrms
and CAST(tgt.Population AS [real])= source.Population
and CAST(tgt.AveOccup AS [real]) = source.AveOccup
and CAST(tgt.Latitude AS [real]) = source.Latitude
and CAST(tgt.Longitude AS [real]) = source.Longitude)
WHEN MATCHED THEN
UPDATE SET tgt.target = CAST(source.variable_out1 AS [real]) ;
END
Conclusion
This article is only for information. We do not claim any guarantees regarding its completeness or accuracy. Nonetheless, we hope this article is useful. Lastly, the feature image is taken from a Microsoft blog, since the image aptly summarizes the contents of the article.