
A key requirement to successful MLOps practice is the ability to build and maintain reliable and repeatable training pipelines, also called Machine Learning Retraining Pipelines.
In one of my linkedin posts, I said that a Machine Learning Training Pipeline is like an ETL pipeline. It extracts data, performs transformations, and outputs a model. Hence, similar to ETL pipelines, these pipelines need to be refreshed in some cadence. However, unlike the ETL pipelines, there are nuances. Besides, let’s get some basics out of the way before we talk about the cadence at which Retraining pipeline should run. Moreover, we will also walkthrough the stages/maturity of Machine Learning Retraining pipelines.
Types of model updates
A Machine Learning team can perform Model Updates in two cases:
Model iteration
A new feature is added to an existing model architecture, or the model architecture is changed. This process is like a new Feature/Change Request. Here, The entire ML Lifecycle is repeated, right from EDA, to Experimentation to rebuilding the training pipeline.
Data iteration
The model architecture and features remain the same, but you refresh this model with new data. Automated Retraining pipelines apply to this scenario where only the data changes its statistical properties while the Model Configuration and Features remain unchanged.
Retraining Cadence
You can automate the ML production pipelines to retrain the models with new data, depending on your use case. There are four broad cases:
Ad-hoc retraining
- On-demand: Ad-hoc manual execution of the pipeline.
-
On availability of new training data: New data isn’t systematically available for the ML system and instead is available on an ad-hoc basis when new data is collected and made available in the source databases.
Interval based retraining
New, labelled data is systematically available for the ML system on a daily, weekly, or monthly basis.
Performance-based retraining
The model is retrained when there is noticeable performance degradation. This needs ground truth from the end user/application.
Data changes based Retraining
On significant changes in the data distributions.
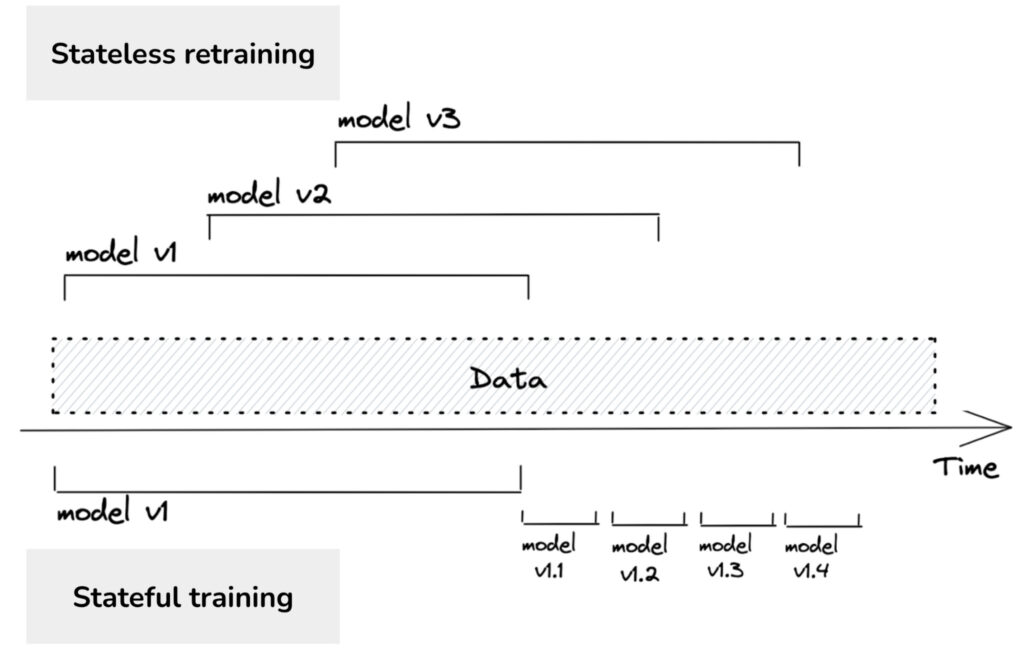
Stateless vs Stateful Retraining
Most companies do stateless retraining—the model is trained from scratch each time. Stateful training is also known as fine-tuning or incremental learning.
Stateful training allows you to update your model with fewer data. Training a model from scratch requires a lot more data than fine-tuning the same model. For example, if you retrain your model from scratch, you might need to use all data from the last three months. However, if you fine-tune your model from yesterday’s checkpoint, you only need to use data from the last day.
Levels of Retraining
Based on the above paradigms, below are the four stages of a Retraining workflow:
Level 1. Manual Stateless Retraining
At this level, updating a model is manual and ad hoc. A data scientist queries the data warehouse for fresh data, cleans it, extracts features from it, retrains that model from scratch on the entire data, and then exports the updated model into a binary format. Then an ML Engineer/Software Engineer takes that binary format and deploys the updated model.
This is a tedious, manual process and often prone to bugs, due to lack of appropriate automated processes(tactical phase of MLOps)
Level 2. Automated Stateless Retraining
Most companies with somewhat mature ML infrastructure are at this level. Some sophisticated companies run experiments to determine the optimal retraining frequency. However, for most companies in this stage, the retraining frequency is set based on gut feeling.
Level 3. Automated Stateful Retraining
In level 2, each time you retrain your model, you train it from scratch (stateless retraining). It makes your retraining costly, especially for retraining with a higher frequency. Hence, you reconfigure your automatic updating script so that, when the model update is kicked off, it first locates the previous checkpoint and loads it into memory before continuing training on this checkpoint.
Level 4. Continual Learning
At level 3, your models are still updated based on a fixed cadence. However, finding the optimal schedule isn’t straightforward and can be situation-dependent. Hence, instead of relying on a fixed schedule, you might want your models to be automatically updated whenever data distributions shift and the model’s performance plummets.
The move from level 3 to level 4 is steep. You’ll first need a mechanism to trigger model updates. This trigger can be:
- Based on a regular interval
- At performance degradation
- Increase in the amount of labeled data
- On a data distribution shift
The key differentiator from level 3 to level 4 is a more intelligent system for model refresh. This should backed by a solid monitoring solution. It ensures that no unnecessary retraining triggers happen.
References:
- Most of the article has been inspired from this blog.
- Also, worth a read is this article on Continuous training.
Featured Image credit . Algorithmia


